debian8系统如何用uniq命令删除文件中的重复行?本教程以debian8系统为例
本配置适用于debian8,9版本
1.uniq检查及删除文本文件中重复出现的行列
语 法:uniq [-cdu][-f栏位>][-s字符位置>][-w字符位置>][--help][--version][输入文件][输出文件]
补充说明:uniq可检查文本文件中重复出现的行列。
2.参 数:
-c 或--count 在每列旁边显示该行重复出现的次数。 -d 或--repeated 仅显示重复出现的行列。 -f
<栏位>
或--skip-fields=
<栏位>
忽略比较指定的栏位。 -s
<字符位置>
或--skip-chars=
<字符位置>
忽略比较指定的字符。 -u 或--unique 仅显示出一次的行列。 -w
<字符位置>
或--check-chars=
<字符位置>
指定要比较的字符。 --help 显示帮助。 --version 显示版本信息。
[输入文件]指定已排序好的文本文件。
[输出文件]指定输出的文件。
3.例如:查看文件file3中重复行数据的内容
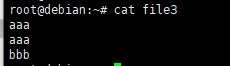
#查看文件file3文件内容 [root@localhost ~]# uniq -d file3 aaa
#file3文件中重复行数据的内容为aaa 查看文件file3中不重复行数据的内容 [root@localhost ~]# uniq -u file3 bbb
显示file3文件每行连续出现的次数
[root@localhost ~]# uniq -c file3 2 aaa 1 bbb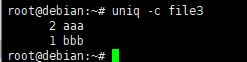
显示file3文件所有重复的行,每个重复的行都显示
[root@localhost ~]# uniq -D file3 aaa aaa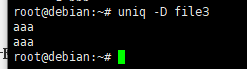
)
 工信部备案号:
工信部备案号: 公安部备案号:
公安部备案号: